
Is it time to delete your staging environment?


A couple of months ago, our platform suffered a 44 minute API outage. It was the first period of downtime we had experienced in over 18 months, and it was really, really frustrating. You can read our post-mortem here.
For us, the troubling part was that the code that broke production had worked perfectly in our staging environment, which is running on an identical stack. How did this happen?
A discrepancy in data between the two environments caused a database migration to fail which in turn knocked us offline. This code had sailed through both our automated tests and staging environment builds multiple times, with green ticks all the way. This gave us a false sense of security around deploying what was a fairly significant code change to production.
It got us thinking; if green builds in staging can still cause a catastrophic outage, what is the point in staging? Let's check why do we compare staging environment vs test environment & why you can easily delete your staging environment?
Why do we even have staging environments?
The goal of a staging environment is to provide a safe place for teams to test their software in an “as-close-to-production-as-possible” environment. As we saw from my example, there is always an opportunity to miss something, rendering the test invalid. So why not just test in production?
Over the last 25 years building software, I have lived through many evolutions and approaches to building software. In almost all of them, staging has been accepted because “we’ve always done it this way”. Taking a first-principles approach to challenging this concept, I thought through the most important changes to building software that I’ve been experienced:
Collaborative Code (Git)
Many teams still struggle to collaborate on code today, but imagine (or think back to) the world without version control. In the late 90’s I remember working in a team passing around USB drives that contained the code we had been working on. While there was some version control software at the time, the adoption was nowhere near what it is with Git today. Building software as a team was extremely difficult and managing source code was a regular pain.
The largest pain points came when you needed to bring everyone’s individual work together and merge. Oftentimes this was owned by a senior developer who would work to create a successful build with the underlying components and run them in a staging environment.
Automated Testing (Selenium)
Any software build process that I’ve been involved in, testing has always been a key step before deployment. With that being said, there has been a massive shift from a focus and resource perspective from “testing” to “production testing” software. The first milestone that I experienced was no doubt automated testing.
Today, people take for granted the world we live in when it comes to testing software. Prior to 2004 and the launch of Selenium, the world we built software within was about unit tests. Basically, you tested the parts and hoped that the sum was at least equal. Selenium allowed us, as developers, to focus on the end user functionality vs. the interoperability of components. This trend has accelerated to the point where we now argue over whether unit testing even makes sense.
Zero Downtime Deployments (Virtualization, Containerization)
Thankfully, scheduled downtime is a thing of the past. In 1999 I was consulting at a big credit card company in the UK. They had a bunch of Sun E10K servers powering their platform. When they wanted to deploy a new release, they would wait until midnight, go into the server room (which was located in the next office, obviously) and pull the fibre optic cable out of the wall. Then 3 hours later, when the new build was running, they would plug it in again. As you can see, there were tons of opportunities for errors because of the sheer nature of what we were doing. They also took time, and so doing them manually multiple times a day would have been out of the question.
Achieving Zero downtime deployments that run regularly and reliably can be tricky, and can depend a lot on your technical stack. Platforms like Heroku and AppEngine popularized this approach and provide these features out of the box, but achieving them with a more legacy stack can be much more difficult. With that being said, for teams that are able to run deployments without downtime, the need for staging is drastically reduced.
Testing in Production (Feature Flags / Toggles)
Perhaps the most recent improvement to reducing the need for staging environments has been the ability to decouple the concept of deploy and release in software. This shift in approach was popularized in this article by Martin Fowler when he introduced the concept of feature toggles and their ability to help teams test features in production vs. staging.
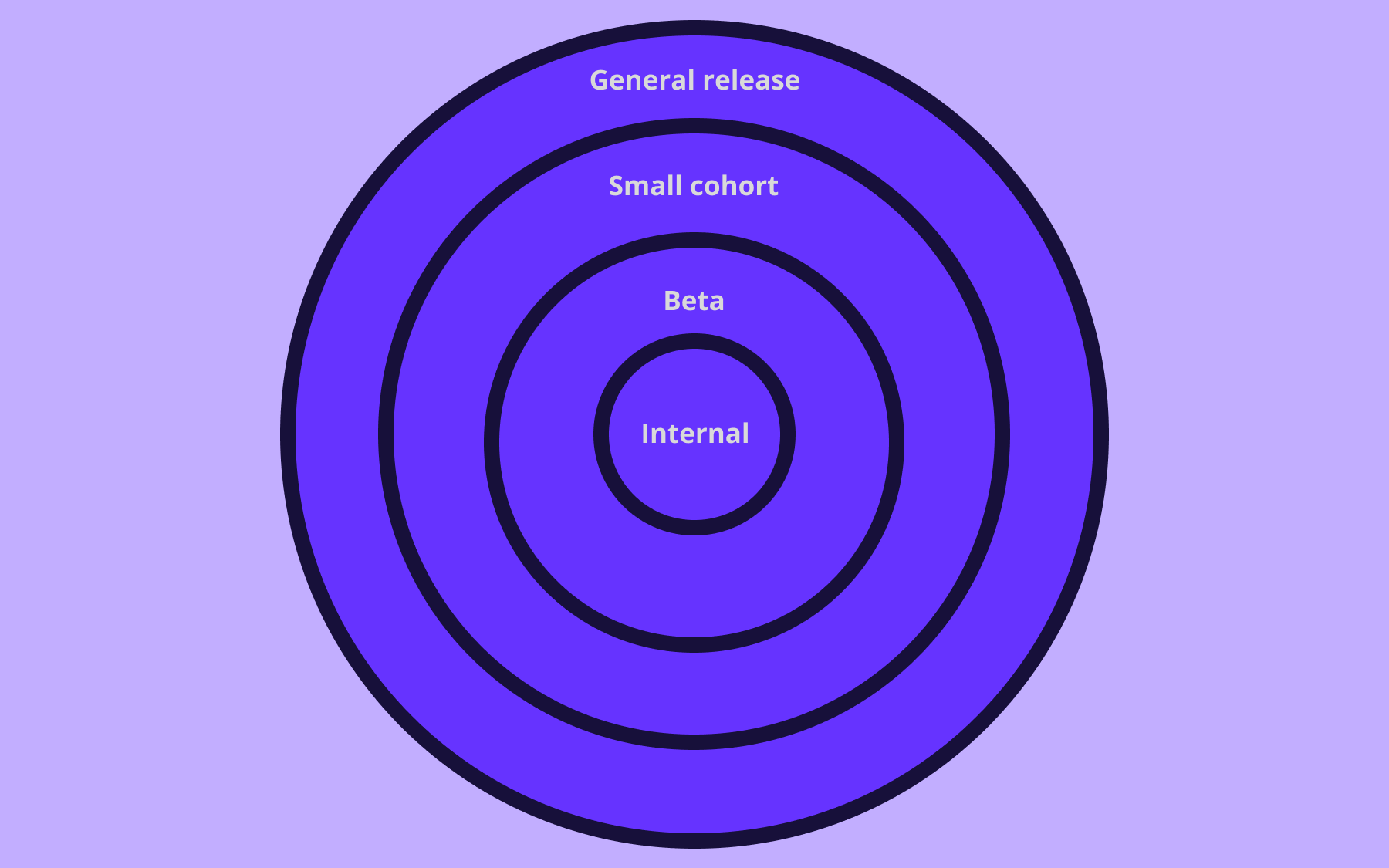
The basic concept of feature flags / toggles is that you deploy the code to production, but you “hide” the feature behind a flag or toggle until you are ready to introduce it to your user base. The core benefit of this approach is that everything your team builds can now be exposed to the actual production environment and you are able to do the most powerful form of making sure your code isn’t broken: testing in production. From this simple concept, many different flavors have arisen: Canary Releases, Kill Switches, Feature Flags, Remote Config (here is a quick story about how to use remote config in your React Native app, a step-by-step tutorial), and A/B Testing.
Stop and think about the underlying benefit of “staging” as we have used it historically. It’s goal is to allow teams to test their code in an environment that is as close to production as possible. Why haven’t we completely evolved to eliminate staging all together?
>>Sing up for free and use feature flags!
OK I get all that, but I’m still terrified…
We believe that there are five engineering pillars that you need to implement before you can consider removing your staging environment. The good thing is that all of these focus points are great engineering practises anyway; so if you really feel like you aren’t ready to delete it just yet, you still get a tonne of benefit from these five pillars.
Pillar 1: A culture of code review and pair programming
Git/GitHub/GitLab have had a hugely beneficial impact on being able to collaborate on code as a team. Code reviews used to involve (if they happened at all!) pulling up a chair and looking at some files in the IDE of the person that wrote the code.
Nowadays, the Merge Request UIs in GitHub/GitLab are critically important parts of the engineering process, allowing teams to collaborate on code review in a way that was just not possible back in the day.
Without a staging environment, writing core application code that could cause downtime or a loss in revenue might seem daunting, but it’s important to remember that pair programming is a super helpful process in this situation, and the tools to perform pair programming, in particular in a remote working environment, are getting better all the time. If you are nervous about the code you are writing, grab a colleague!
Pillar 2: Automated Testing, build pipelines, and zero-downtime deployments
If you are pushing to production multiple times a day, you need to be able to rely on the tooling you use to get that code into production. The goal is to prevent any bugs ever getting to production. That’s impossible, but you can work on catching as many as you possibly can! This means really good test coverage across your entire code base. That includes unit testing, integration testing, end to end testing, browser testing, and then non-functional testing like latency/performance
Pillar 3: Decoupling deploy and release
Feature Flags are instrumental in being able to test in production, and being comfortable deploying code regularly whilst maintaining control over the actual release of the feature itself.
Using a feature flagging platform like Flagsmith allows you to be really expressive in terms of who sees your new features and when they see them. You can use tools like Flagsmith to show new features to individuals and specific groups of users before rolling them out to your wider audience over time. By the way, check the difference between decoupling deploy and release.
Pillar 4: Really good monitoring
That doesn’t mean pointing Pingdom at one API endpoint and you’re done! You need to monitor your stack at a variety of points:
- Test meaningful API endpoints that connect with your datastores and any other third party services that you rely upon
- Test non functional aspects like latency, load and overall end client performance using tools like DebugBear.
- Have an alerting system that people use and that works!
Pillar 5: Meaningful post mortems
It’s really important to keep in mind that bugs will always happen, and outages will always happen, regardless of whether you have a staging environment or not. The thing to remember is that you can work to reduce these outages through processes and tools, but the most important way you can reduce bugs and outages is with meaningful post mortems:
- Carry out a root cause analysis on what happened and why
- Communicate that with your team and your users about what happened, what you have learnt and how you are going to use that learning to improve.
- Figure out how to prevent it from happening again in the future. This is the hard part! It will likely consist of a combination of new code, infrastructure and processes.
I really like staging though?
You can take small steps to get there. There are a bunch of things you can do to dip your toe in the water and get a feel for what life would be like without staging.
If you have a web application, deploying the web front end is a perfect candidate as the first component in your stack going straight to production. There are a number of reasons for this:
- Platforms like Vercel provide great integrations with git and allow you to version every single push of your application, allowing you to easily roll back if something goes wrong.
- Front end web applications lend themselves perfectly to feature flagging. Using flags to show and hide UI elements is their primary use case, so you can leverage flags to their full effect.
- Front ends are generally stateless, meaning you don’t have to worry about thorny issues like database migrations.
- If your front end is working against a stable API, you don't really need to worry about versioning compatibility with other parts of your stack.
Another option is to select some less invasive features and branches that don't really get any benefit from going through the staging and sign off process. If you have a feature branch that updates copy or changes styling in your application, that is a prime candidate to go straight to production.
Staging environment vs Test environment. Should you kill your staging environment?
Depending on where you are in your product team lifecycle, implementing these pillars may well involve a lot of work. It’s much easier to implement them and their processes at the beginning of a project.
The thing to remember is that, regardless of the end state, working on these pillars will get you a ton of benefits, even if you don’t turn off your staging environment… just yet. These pillars will definitely help improve your overall velocity and code quality.
If you start off deploying smaller features directly to production, you can increase the scope of this over time. One day you may well realise that you haven’t pushed anything through the staging environment for weeks.
In many ways, removing staging can be seen as a panacea. For some teams, and some products, it’s just too hard, for whatever reason (and some of them will be good reasons!). For us at Flagsmith, we are going to split out our production API between the (very!) high traffic SDK API and everything else that powers our dashboard. For the “everything else” part of the API, we have a goal of deploying to production for that API.
But for a piece of infrastructure that serves thousands of requests per second, 24 hours a day, and that hundreds of companies rely on to power their feature flags, we’re just not ready for that yet. And we’re fine with that. For now.
































OpenTelemetry, without the vendor lock-in: Introducing full observability for Open Source and Self-Hosted Flagsmith customers


































































.png)
.png)

.png)

.png)



.png)









.webp)